基于强化学习的运控示例-V1.2.1
说明
参考项目:
-
https://github.com/UBTECH-Robot/TienKung-Lab
该代码库是一个基于强化学习的运动控制系统,专为全尺寸人形机器人天工(TienKung)设计。它将AMP风格的奖励与周期性步态奖励相结合,促进了自然、稳定和高效的行走和跑步行为。
该代码库建立在IsaacLab上,支持Sim2Sim迁移到MuJoCo,并具有模块化架构,便于无缝定制和扩展。此外,它还集成了基于光线投射的传感器,以增强感知能力,能够精确地与环境进行交互和避障。该框架还已经在真实的天工机器人上成功验证。
-
https://github.com/UBTECH-Robot/Deploy_Tienkung
该代码库下有两个目录,
rl_control_new和x_humanoid_rl_sdk。其中的
rl_control_new是基于ROS2的人形机器人强化学习控制库,用于控制天工系列人形机器人。该库使用强化学习算法实现机器人运动控制,支持仿真和真实机器人环境。另一个
x_humanoid_rl_sdk是天工人形机器人强化学习控制SDK,包含状态机实现、机器人接口和控制算法。
此指引文档在参考项目基础上,解决了一些编译及配置问题。
- 适配机型:天工行者(Lite)。天工无界(Plus)及天工无疆(Pro)版本将在26年Q1支持
- 操作系统:ubuntu 22.04
- 系统架构:x86
- 推荐GPU:Nvidia RTX 30系列及以上,显存16G及以上
- 最低系统配置:磁盘 512G ,内存16G
- 如果git等资源拉取过慢,建议使用代理
软件包
将 TienKung-Lab.zip 和 ros_lite_src.zip 两个包下载后放到 ~/ 目录下。
~/ # 软件包
├── TienKung-Lab.zip # 步态训练包
├── ros_lite_src.zip # 步态部署包
一、基础软件
1、CUDA
安装CUDA 。
建议正确安装最新Nvidia驱动后,使用 nvidia-smi查看驱动配套的CUDA版本,在 https://developer.nvidia.com/cuda-toolkit-archive 中选择对应的CUDA Toolkit下载。这里以12.8版本CUDA为例。
cd ~/
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
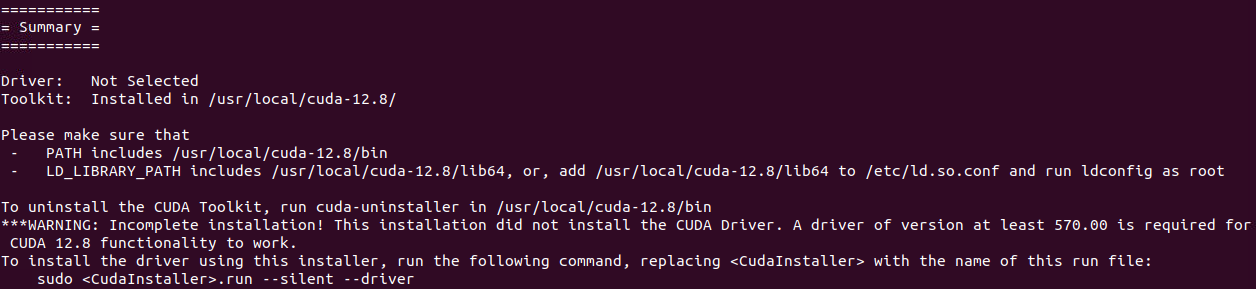
sudo sh cuda_12.8.0_570.86.10_linux.run
# 设置环境变量 ~/.bashrc
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
# 立即生效
source ~/.bashrc
2、Conda
安装miniconda,一直选择yes完成安装。
cd ~/
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash ./Miniconda3-latest-Linux-x86_64.sh
安装完毕后检查.bashrc文件内有无设置conda环境变量。
cat ~/.bashrc
3、IsaacSim
安装isaacsim 4.5。下载并解压软件包后,创建env_isaacsim环境,进入env_isaacsim环境后安装。
参考链接:https://docs.isaacsim.omniverse.nvidia.com/4.5.0/installation/install_workstation.html
mkdir ~/isaacsimdir
cd ~/isaacsimdir
wget https://download.isaacsim.omniverse.nvidia.com/isaac-sim-standalone-4.5.0-linux-x86_64.zip
unzip "isaac-sim-standalone-4.5.0-linux-x86_64.zip" -d ~/isaacsimdir
conda create -n env_isaacsim python=3.10
conda activate env_isaacsim
./python.sh -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
./post_install.sh
./isaac-sim.selector.sh
conda deactivate
4、IsaacLab
安装IsaacLab 2.1.0。下载并解压软件包后,创建env_isaaclab环境,进入env_isaaclab环境后安装。
可从Installing Isaac Lab部分开始参考。
sudo apt install git
mkdir ~/isaaclabdir
cd ~/isaaclabdir
wget https://github.com/isaac-sim/IsaacLab/archive/refs/heads/release/2.1.0.zip
unzip "2.1.0.zip" -d ~/isaaclabdir
cd IsaacLab-release-2.1.0
ln -s ~/isaacsimdir ~/isaaclabdir/IsaacLab-release-2.1.0/_isaac_sim
~/isaaclabdir/IsaacLab-release-2.1.0/isaaclab.sh --conda env_isaaclab
conda activate env_isaaclab
sudo apt install cmake build-essential
~/isaaclabdir/IsaacLab-release-2.1.0/isaaclab.sh --install
conda deactivate
- 执行
./isaaclab.sh --install时如果提示权限不足,很可能是 _isaac_sim 目录对应的链接目录没有权限,可尝试修改。 - 如果提示pip包冲突,可先不理会,等待
--install执行完后直接尝试后续的步骤,看是否可正常开始训练。
对于50系列GPU,请使用最新的PyTorch nightly版本,而不是Isaac Sim自带的PyTorch 2.5.1:注意链接中的cu128要与自己的CUDA配套。
~/isaaclabdir/IsaacLab-release-2.1.0/isaaclab.sh -p -m pip install --upgrade --pre torch --index-url https://download.pytorch.org/whl/nightly/cu128
二、步态训练及部署
1、解压代码
cd ~/
unzip TienKung-Lab.zip
2、安装环境
-
安装与CUDA配套的pytorch版本。例如可以到 https://mirrors.nju.edu.cn/pytorch/whl/ 查看对应版本,然后更新到对应pip指令中。注意链接中的【cu128】要与自己的CUDA版本配套。
-
后续命令都需要进入
conda activate env_isaaclab环境才能正常运行。
conda activate env_isaaclab
cd ~/TienKung-Lab
pip install -e .
pip install -U --index-url https://mirrors.nju.edu.cn/pytorch/whl/cu128/ torchvision==0.24.0 torch==2.9.0
pip uninstall -y rsl-rl-lib || true
cd ~/TienKung-Lab/rsl_rl
pip install -e .
pip install onnxscript
3、训练
使用 tienkung/datasets/motion_amp_expert 中的 AMP 参考运动数据来训练策略。
AMP(Adversarial Motion Priors)最早由学术界提出:
在使用欠约束奖励函数训练高维度的仿真智能体时,往往会导致智能体学到在物理上不可行的策略,而这些策略在部署到真实世界时是无效的。为缓解这类不自然的行为,强化学习研究者通常会设计复杂的奖励函数,以鼓励物理上合理的行为。然而,手工设计奖励往往需要繁琐且劳动密集的调参过程,并且这类奖励函数难以在不同平台和任务之间泛化。学术界提出,用从动作捕捉示例数据集中学习得到的“风格奖励(style rewards)”来替代复杂的奖励函数。学习得到的风格奖励可以与任意任务奖励相结合,从而训练出在完成任务的同时,采用自然运动策略的控制策略。这些自然的运动策略同样有助于向真实世界的迁移。
所以这里的AMP 参考运动数据到底是什么?它实际上是一段“动作很像人的参考运动轨迹”。
普通强化学习,只能设定类似如下的奖励:
- 不摔倒 +1
- 速度接近目标 +1
- 能量小 +1
结果通常会如下:
- 步态奇怪、抖动、僵硬
- 像“机械怪物” 但数值上完全合法。
原因是奖励函数难以完整描述“人类的自然动作”。而将这里的AMP 参考运动数据是提供给算法,则可在训练时判定:“这个动作和给出的参考运动数据相似度如何?”,进而给出奖励,完成训练。
参数:
- --task 任务类别,有walk、run
- --headless 不显示界面训练
- --num_envs 场景中机器人数量
- --max_iterations 训练迭代次数,默认值为50000
开始训练
cd ~/TienKung-Lab
python legged_lab/scripts/train.py --task=walk --headless --logger=tensorboard --num_envs=2048
- 如果使用默认的训练迭代50000次,在RTX4090显卡上,大概需要18个小时。
- 目前软件包支持天工行者(Lite),天工无界(Plus)及天工无疆(Pro)会在26年Q1添加。
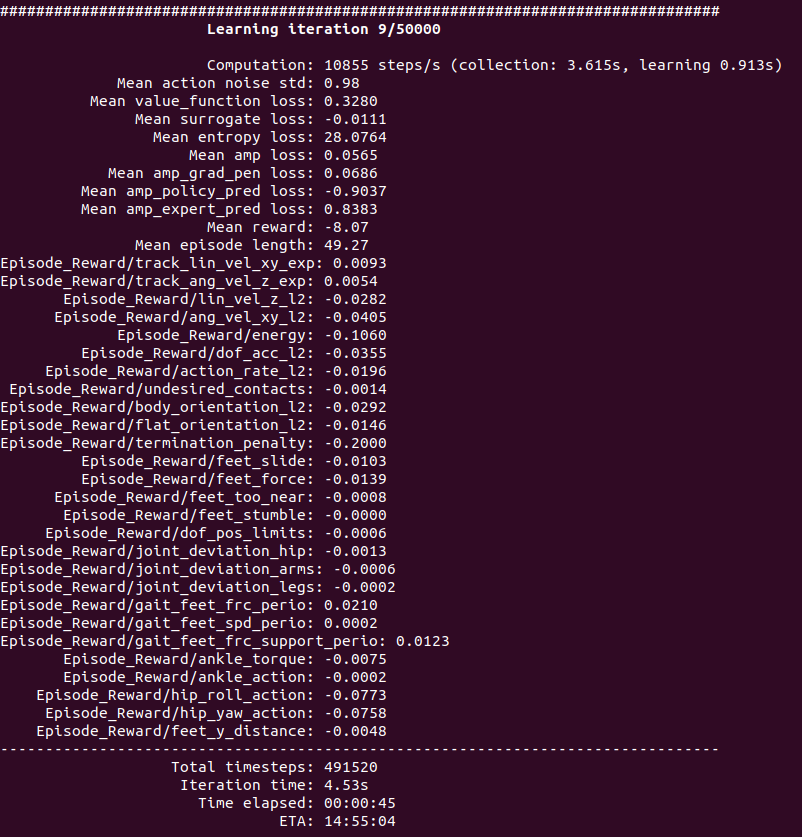
模型位置在:~/TienKung-Lab/logs/walk/xxxx/model_xxx.pt,这里的pt文件是模型,xxxx 是训练开始时候以时间戳为名的文件夹,例如:
~/TienKung-Lab/logs/walk/202x-01-12_05-07-14/model_100.pt~/TienKung-Lab/logs/walk/202x-01-12_05-07-14/model_49900.pt
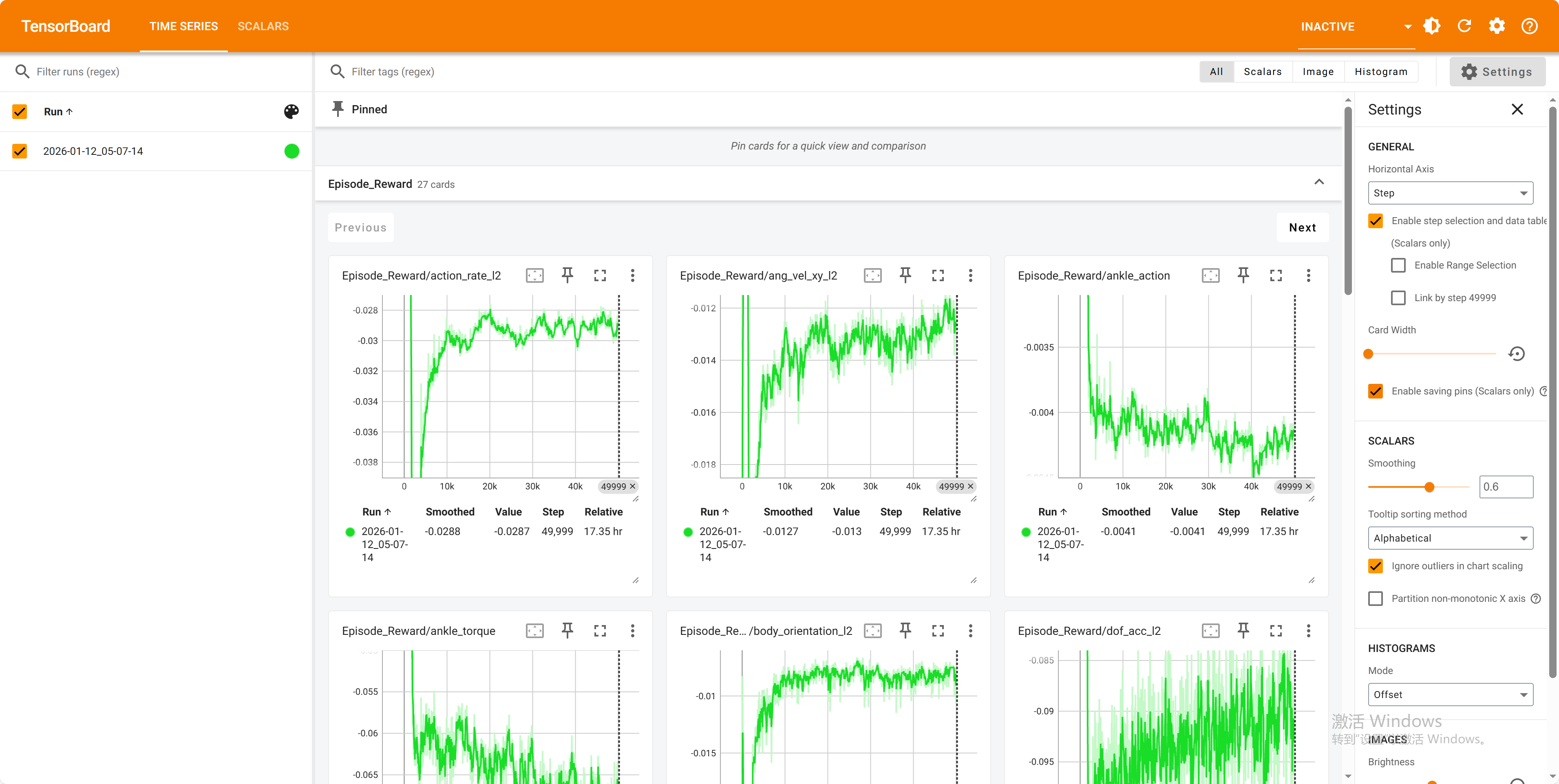
查看训练情况
可以打开一个新终端,查看训练情况:
conda activate env_isaaclab
cd ~/TienKung-Lab
tensorboard --logdir=logs/walk

4、恢复训练
cd ~/TienKung-Lab
mkdir ~/TienKung-Lab/logs/walk/pretrained
# Copy the PT file to folder【pretrained】
python legged_lab/scripts/train.py --task=walk --headless --logger=tensorboard --num_envs=2048 --resume=True --load_run=pretrained --checkpoint=model_8100.pt
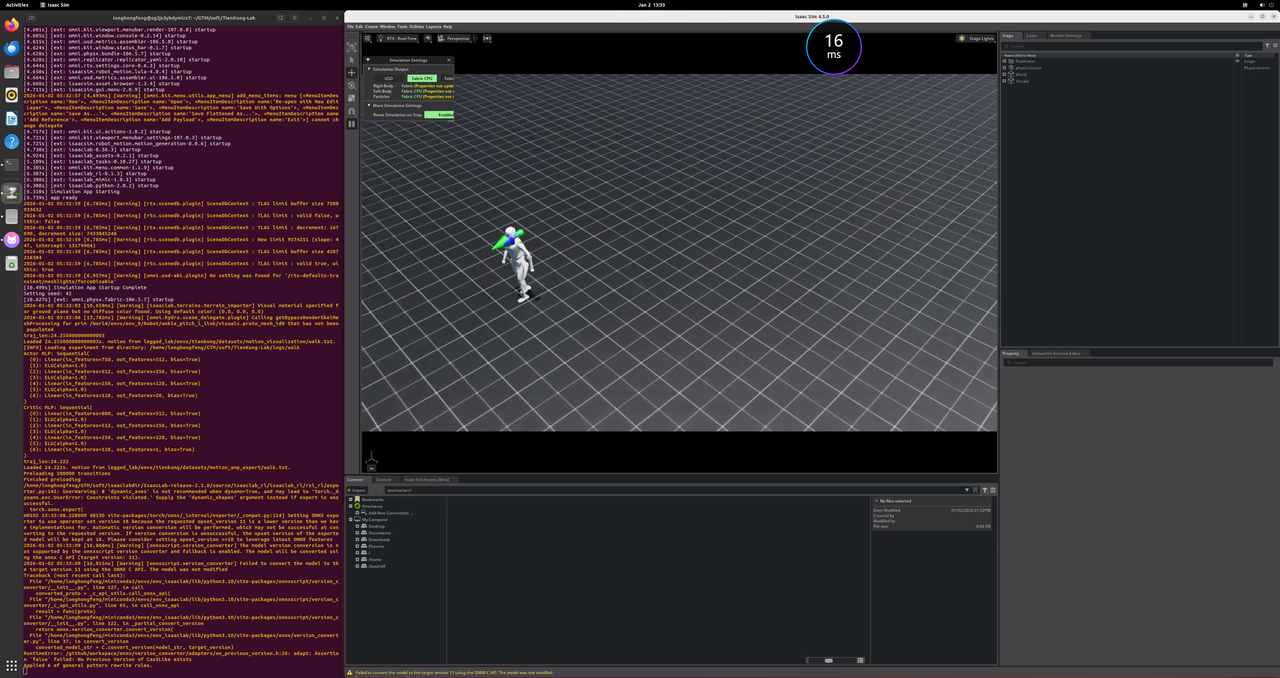
5、仿真环境运行(Isaac Lab)
在 Isaac Lab 仿真环境中加载和运行已训练的模型。
- --task 任务类别,有walk、run
- --num_envs 场景中机器人数量
- --load_run
.pt文件所在的目录,默认使用最新训练生成的目录 - --checkpoint
.pt文件的文件名,默认使用最新训练出来的文件
cd ~/TienKung-Lab
mkdir ~/TienKung-Lab/logs/walk/exe
# 将要运行的.pt文件复制到 exe 目录,例如:~/TienKung-Lab/logs/walk/exe/model_49900.pt
python legged_lab/scripts/play.py --task=walk --num_envs=1 --load_run=exe --checkpoint=model_49900.pt
play.py 脚本同时会将本次运行所使用的的模型导出为 .pt 和 .onnx 两种格式的文件到同目录的 exported/ 子目录内以备用,例如:
~/TienKung-Lab/logs/walk/exe/exported/policy.pt~/TienKung-Lab/logs/walk/exe/exported/policy.onnx
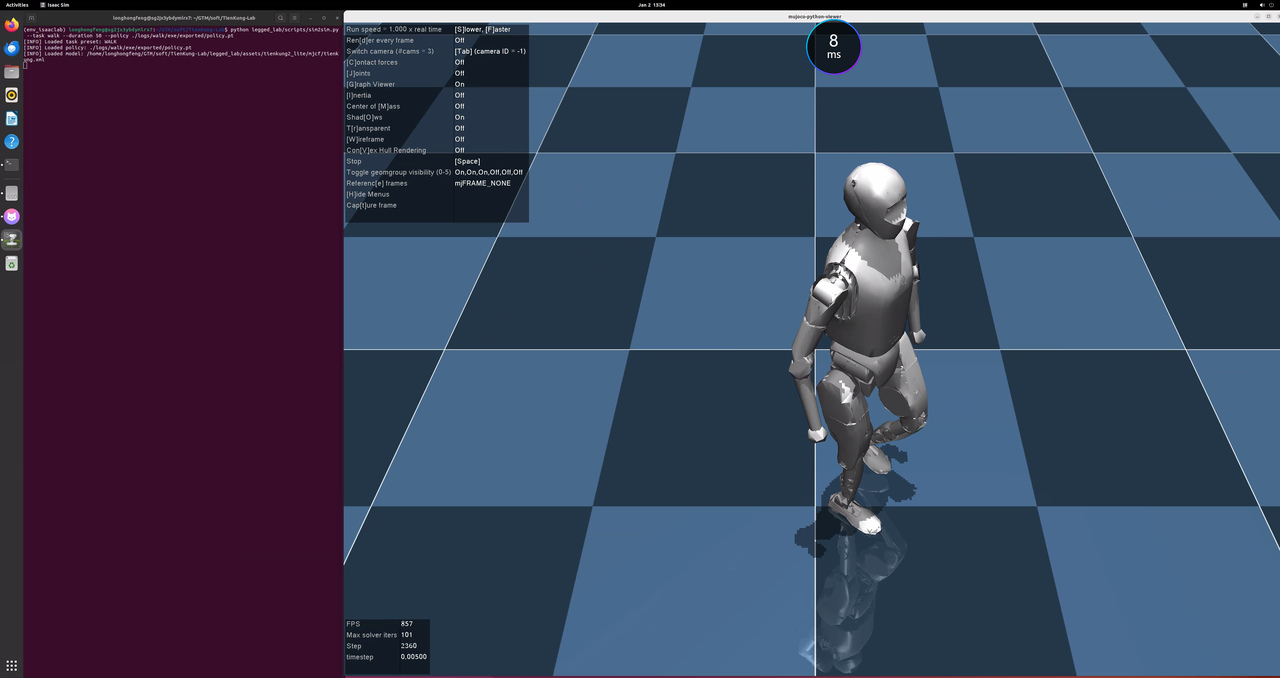
6、Sim2Sim (MuJoCo)
在 MuJoCo 中加载验证训练好的模型,以执行交叉仿真验证。
在前述【运行】步骤中执行 play 脚本时,训练好的模型会自动导出并保存到同目录的下的 exported/ 子目录,在这里可直接用 --policy 参数指定即可。
cd ~/TienKung-Lab
python legged_lab/scripts/sim2sim.py --task walk --duration 50 --policy ./logs/walk/exe/exported/policy.pt
7、模型转换
使用OpenVINO模型转换,得到 bin和xml 文件。
cd ~/TienKung-Lab
pip install openvino
ovc logs/walk/exe/exported/policy.pt --output_model logs/walk/exe/exported/
8、本地部署
将训练好的运控模型部署到训练机器的 ros_lite 项目内。
复制模型文件
模型转换后的 .bin、.xml 文件以及训练得到的 .pt 文件,都复制到 ~/ros_lite/install/rl_control_new/share/rl_control_new/config/policy/ 目录下。
cd ~/
unzip ros_lite_src.zip -d ros_lite
cd ~/TienKung-Lab/logs/walk/exe/exported/
cp policy.pt policy.bin policy.xml ~/ros_lite/install/rl_control_new/share/rl_control_new/config/policy/
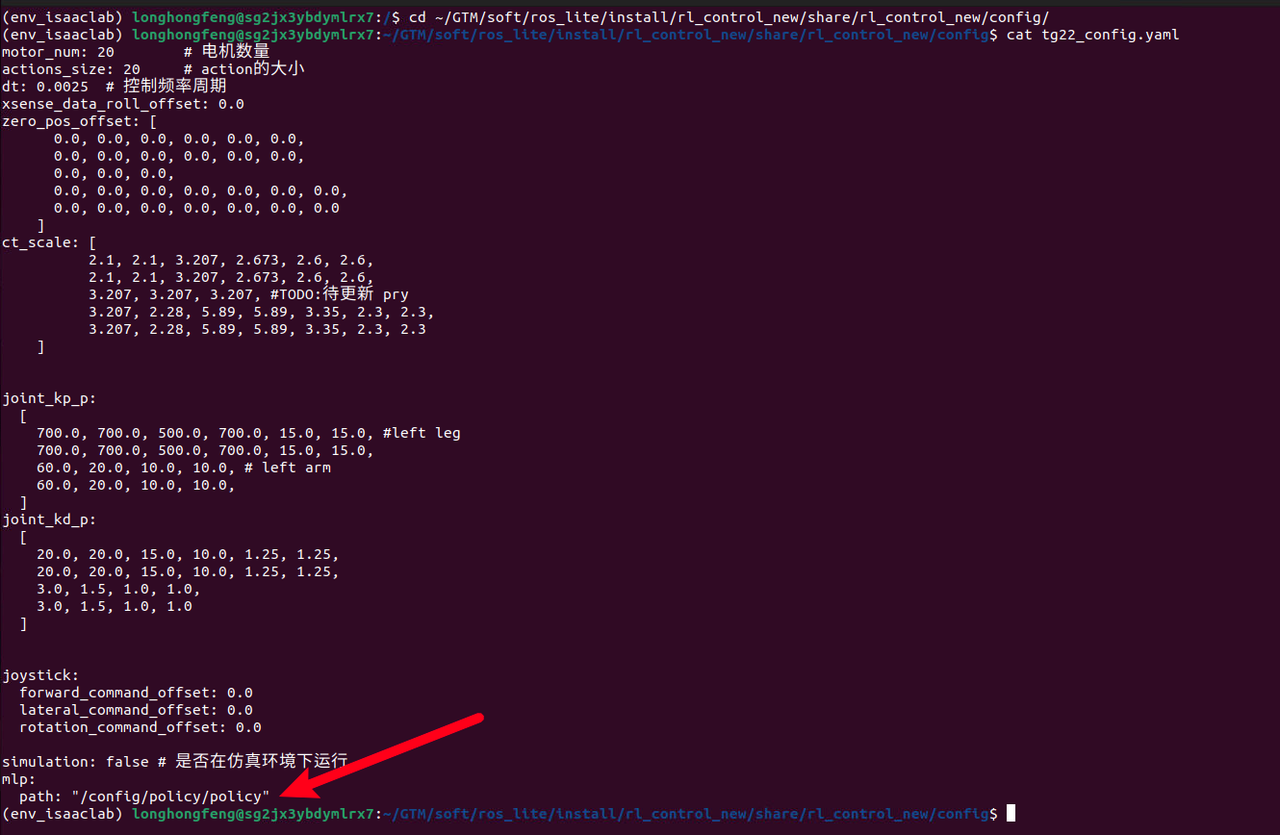
确保使用正确的模型文件
请确认 ~/ros_lite/install/rl_control_new/share/rl_control_new/config/tg22_config.yaml 配置文件内 mlp.path 指向的是正确的刚刚训练出来的模型的名称,不需要后缀。
例如,如果训练出来的模型文件有policy.pt 和 policy.bin 和 policy.xml,则配置文件内 mlp.path 值应该设置为 /config/policy/policy 即可。
cd ~/ros_lite/install/rl_control_new/share/rl_control_new/config/
cat tg22_config.yaml
真正用来做运动控制的模型文件是 .bin 和 .xml。
这里是将模型文件直接复制到 ros_lite 项目的编译后目录了,适用于在真机上不再编译的场景。
如果在真机上还会再做编译,可将模型文件复制到 ~/ros_lite/src/rl_control_new/config/policy 目录,等将项目复制到真机上后再做编译即可。
9、真机部署
将训练机器上的 ~/ros_lite 目录整体打包,放置到天工行者的192.168.41.1的x86板内并解压在 /home/ubuntu/ 目录。至此,就已将步态训练的模型部署到了天工真机。
准备测试
- 先在192.168.41.1的x86板上,确保机器人自启动服务是关闭的:
sudo systemctl status proc_manager.service - 检查服务的状态是否为disable,如果不是,手动disable:
然后断电重启整个机器人,等待重启完成。
sudo systemctl disable proc_manager.service - 到192.168.41.1的x86板上手动启动本体服务:
tmux
sudo su
cd ros2ws
source install/setup.bash
ros2 launch body_control body.launch.py - 另外启动一个终端,启动本次训练的强化学习运控
tmux
cd ~/ros_lite
source install/setup.bash
ros2 launch rl_control_new rl.launch.py
由于是新训练出来的模型,效果无法保证,所以一定要确保安全:
- 机器人一定要用绳子连接在移位机上,绳子不要太松以免紧急时机器人下坠的力量过大造成危险
- 并且另外有一个人随时准备好按下急停按钮
遥控器按键说明
| 按键 | 功能 |
|---|---|
| A键+G键(拨至中间零位) | 切换到MLP(机器学习策略)控制模式 |
| D键 | 切换到ZERO(回零)控制模式 |
| C键 | 切换到STOP(停止)控制模式 |
| 左摇杆 | 控制机器人前进/后退和左移/右移 |
| 右摇杆 | 控制机器人转向(左转/右转) |
启动这个运控服务,按 A 时会直接从回零状态直接进入到行走状态,没有站立状态!尤其需要注意。
控制逻辑说明
- 机器人初始状态为STOP模式,启动后按ZERO模式可确保机器人所有关节都回到设置的零位状态
- 按A键+G键(拨至中间零位) 切换到MLP模式,机器人开始行走,注意,不会进入站立状态!
- 按D键回到ZERO模式,机器人回到初始姿态
- 按C键进入STOP模式,保持当前姿态
- 状态切换流程为:STOP -> ZERO -> MLP -> STOP
然后可以在确保安全的前提下,逐步用遥控器操作机器人回零,行走。
参考:https://github.com/Open-X-Humanoid/Deploy_Tienkung/tree/main/rl_control_new