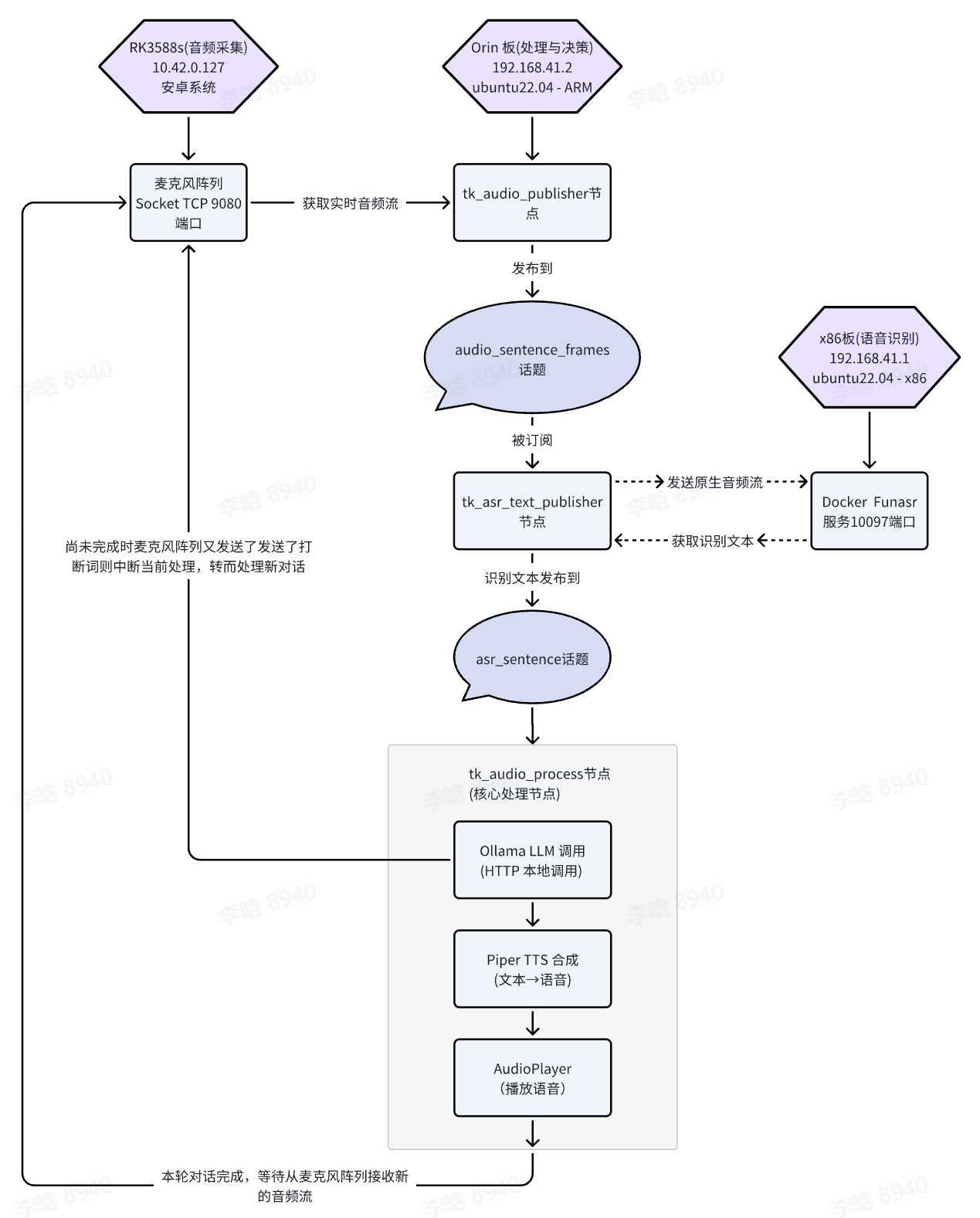
3.2.系统架构
硬件拓扑结构
项目使用多机器协同架构,Orin 板是整个系统的核心编排者:
IP 地址配置
| 设备 | IP 地址 | 功能 | 端口 |
|---|---|---|---|
| RK3588s | 10.42.0.127 | 音频采集与播放 | 9080 |
| Orin 板 | 192.168.41.2 | ROS 2 系统 + Ollama LLM + Piper TTS | 11434 |
| x86 服务器 | 192.168.41.1 | Funasr ASR 服务 | 10097 |
网络通信协议详解
1. RK3588s ↔ Orin 板(Socket TCP)
RK3588s 麦克风
↓
音频流 (16000 Hz, 16-bit PCM)
↓
Socket TCP 连接 (10.42.0.127:9080)
↓ (发送原始音频)
tk_audio_publisher (通过VAD字段判断并接收整句的音频)
↓
ROS audio_sentence_frames 话题
↓
tk_asr_text_publisher (订阅)
其中RK3588s板上9080端口提供的TCP数据包(详细代码在 src\audio_service\audio_service\socket_audio_provider.py 文件),下文会有详细的说明。
2. Orin 板 ↔ x86 服务器(WebSocket)
tk_asr_text_publisher (Orin 板)
↓
WebSocket Client 连接
↓
192.168.41.1:10097 (x86 服务器 Funasr)
↓
发送整句音频
↓
Funasr 模型识别
↓
返回识别结果
↓
获得最终识别文本
3. Orin 板内部(本地 Ollama + Piper TTS)
tk_audio_process (收到识别文本)
↓
Ollama LLM Client (HTTP)
↓
localhost:11434/api/chat (本地 Ollama 服务)
↓
qwen2.5:1.5b 模型流式生成回答
↓
等待流式返回适合作为一个分句播放的回答文本后
↓
Piper TTS (本地调用)
↓
ONNX 模型推理:文本→语音波形
↓
AudioPlayer 播放
↓
持续播放直到Ollama LLM Client生成结束
关键点总结
| 层级 | 处理位置 | 技术 | 说明 |
|---|---|---|---|
| 音频采集 | RK3588s | 麦克风阵列 + Socket | 原始音频通过 Socket 发送到 Orin |
| 音频接收与发布 | Orin 板 | tk_audio_publisher (ROS) | 接收原始音频,按整句发布 |
| 语音识别 | Orin 板 发送,x86 处理 | WebSocket + Funasr Docker | Orin 通过 WebSocket 将音频发送给 x86 识别 |
| 文本发布 | Orin 板 | tk_asr_text_publisher (ROS) | 识别结果发布到 ROS 话题 |
| LLM 处理 | Orin 板 | Ollama HTTP API | 本地调用 Ollama,生成回答(流式) |
| TTS 合成 | Orin 板 | Piper ONNX + Pytorch | 本地调用 Piper,生成语音波形 |
| 音频播放 | Orin 板 | AudioPlayer (PyAudio) | 队列式播放,直接在Orin1上进行播放 |