Online voice interaction
Project Overview
The entire project includes the following capabilities:
-
STT (Speech to text) — powered by Microsoft Azure Speech Service.
-
Large Language Model (LLM) — supports only LLM services that can be accessed through the OpenAI SDK.
-
TTS (Text-to-Speech) — powered by Microsoft Azure Speech Service.
Repository:https://github.com/UBTECH-Robot/tkvoice/tree/allonline_public
Reference documentation for integrated cloud services in the allonline_public branch:
- Microsoft Azure STT)
- Microsoft Azure TTS
- 阿里云百炼平台 as a LLM provider,you can also modify it to use other LLM providers that are compatible with the OpenAI API.
Support for different languages depends on Microsoft Speech Services and the LLM provider.
The overall workflow of the two branches is roughly the same. The difference is that the offline-solution branch connects to the locally deployed speech and LLM services on Walker TienKung, while the cloud-solution branch connects to the online services provided by cloud service providers.
To use the allonline_public branch, first pull the project and switch to that branch. Then locate the .env.example file at the same level as src, rename it to .env, and modify the values of the required configuration items.
For the specific configuration:
-
For Microsoft Speech Services, you can refer to the link provided above.
-
For the LLM provider, you can use OpenAI or any other provider that is compatible with the OpenAI API.
1. Code Description
The overall workflow of the application is as follows:
-
On the Orin board, the tk_audio_publisher node receives an audio stream from the RK3588s device and publishes complete sentence-level audio streams to the audio_sentence_frames topic.
-
On the Orin board, the tk_asr_text_publisher node subscribes to the audio_sentence_frames topic. After receiving the raw audio stream, it sends the data to Azure Speech Service using the SpeechRecognizer classes and methods from the azure.cognitiveservices.speech SDK. The recognized text is then published to the asr_sentence topic.
-
The tk_audio_process node on the Orin board subscribes to the asr_sentence topic. After receiving the recognized question text, it sends the query to the configured LLM service using the OpenAI SDK, retrieving the response in a streaming manner. The specific LLM service is configured in the .env file located in the project’s root directory.
infoThe current implementation only uses the OpenAI SDK for requests, so only LLM services compatible with the OpenAI SDK are supported at this stage.
-
During the streaming output of the LLM’s response, whenever enough characters are received to form a complete sentence, the SpeechSynthesizer classes and methods from the azure.cognitiveservices.speech SDK are invoked to convert that sentence into speech. The generated audio is then added to the AudioPlayer playback queue and played sequentially.
2. Configuration instructions
The .env file located in the project’s root directory contains critical configuration parameters. Properly setting up this file is essential for enabling the STT, LLM, and TTS functionalities throughout the entire project. You may create this file if the file does not exist.
LLM Configuration
LLM_KEY=sk-xxx
LLM_ENDPOINT=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_MODEL=qwen-flash
All LLM service providers compatible with the OpenAI SDK will provide the above 3 parameters:
-
LLM_KEYmay also be called "API Key" (e.g., on Alibaba Cloud Bailian Platform). Different providers may use different terminology. -
LLM_ENDPOINTmay also be called "Base URL" (e.g., on Alibaba Cloud Bailian Platform). This is the endpoint for the LLM service you want to use.Taking Alibaba Cloud Bailian Platform as an example, you can refer to the Bailian Platform Official Documentation for node selection and key retrieval. As shown in the image below, you can find available nodes and the link to key management.
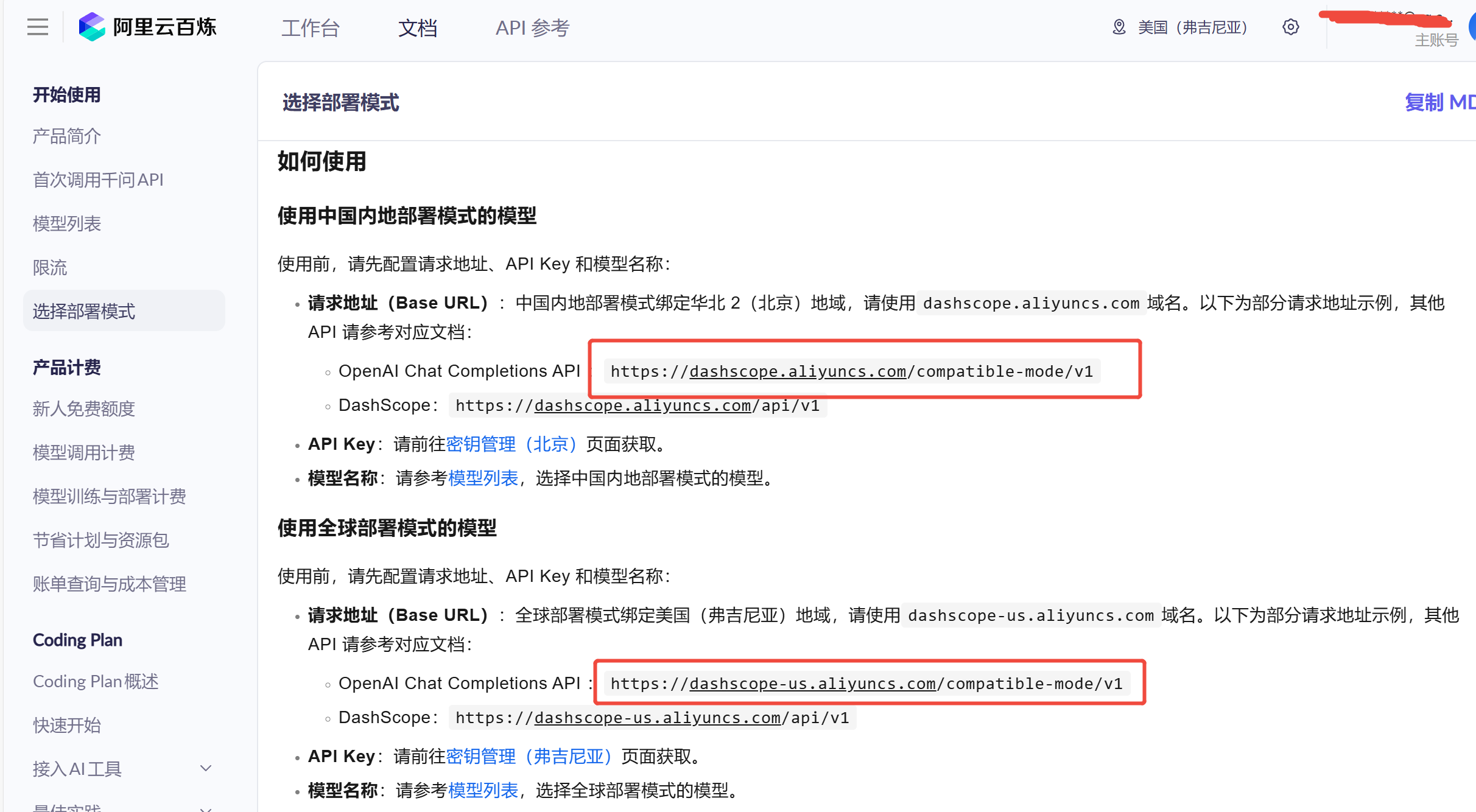
Other providers such as Microsoft, Amazon, or OpenAI should also have global nodes available for selection.
-
LLM_MODELis the name of the model to use. Taking Alibaba Cloud Bailian Platform as an example, available options include qwen3-max, qwen-plus, qwen-flash, etc. Refer to: https://help.aliyun.com/zh/model-studio/models. For Microsoft, Amazon, or OpenAI, there should be other models available as well—users need to explore these on their own. -
For Microsoft LLM options, refer to: https://learn.microsoft.com/en-us/azure/ai-foundry/openai/supported-languages?tabs=dotnet-secure%2Csecure%2Cpython-entra&pivots=programming-language-python
Azure Speech Service Key and Endpoints
SPEECH_KEY="xxx"
STT_ENDPOINT=https://eastasia.stt.speech.microsoft.com
TTS_ENDPOINT=https://eastasia.tts.speech.microsoft.com
STT and TTS currently integrate with Azure Speech Services and require the following parameters:
SPEECH_KEY: The key required to call the serviceSTT_ENDPOINT: Speech-to-text endpointTTS_ENDPOINT: Text-to-speech endpoint
For detailed steps, refer to the Microsoft Speech Service Official Documentation
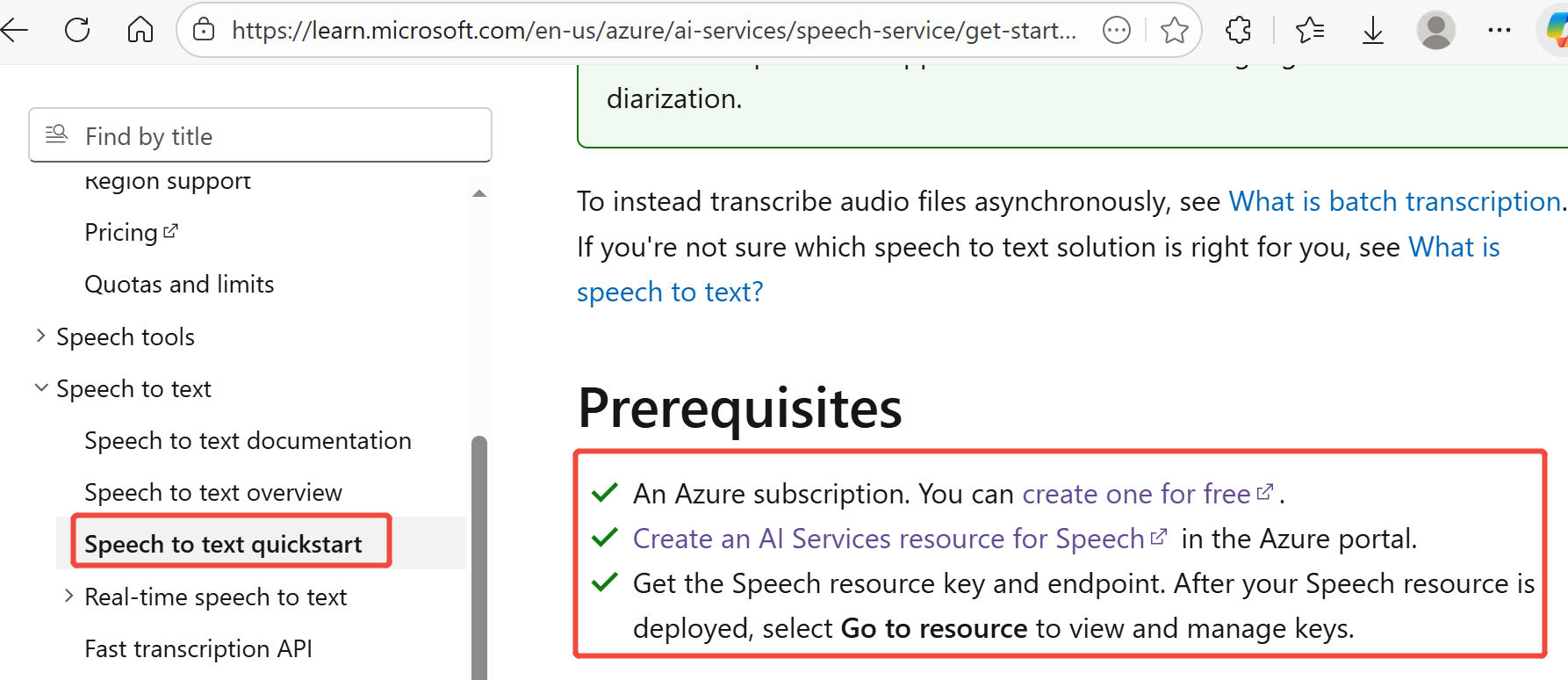
After creating the resource, you can view the required information on the Azure Portal:
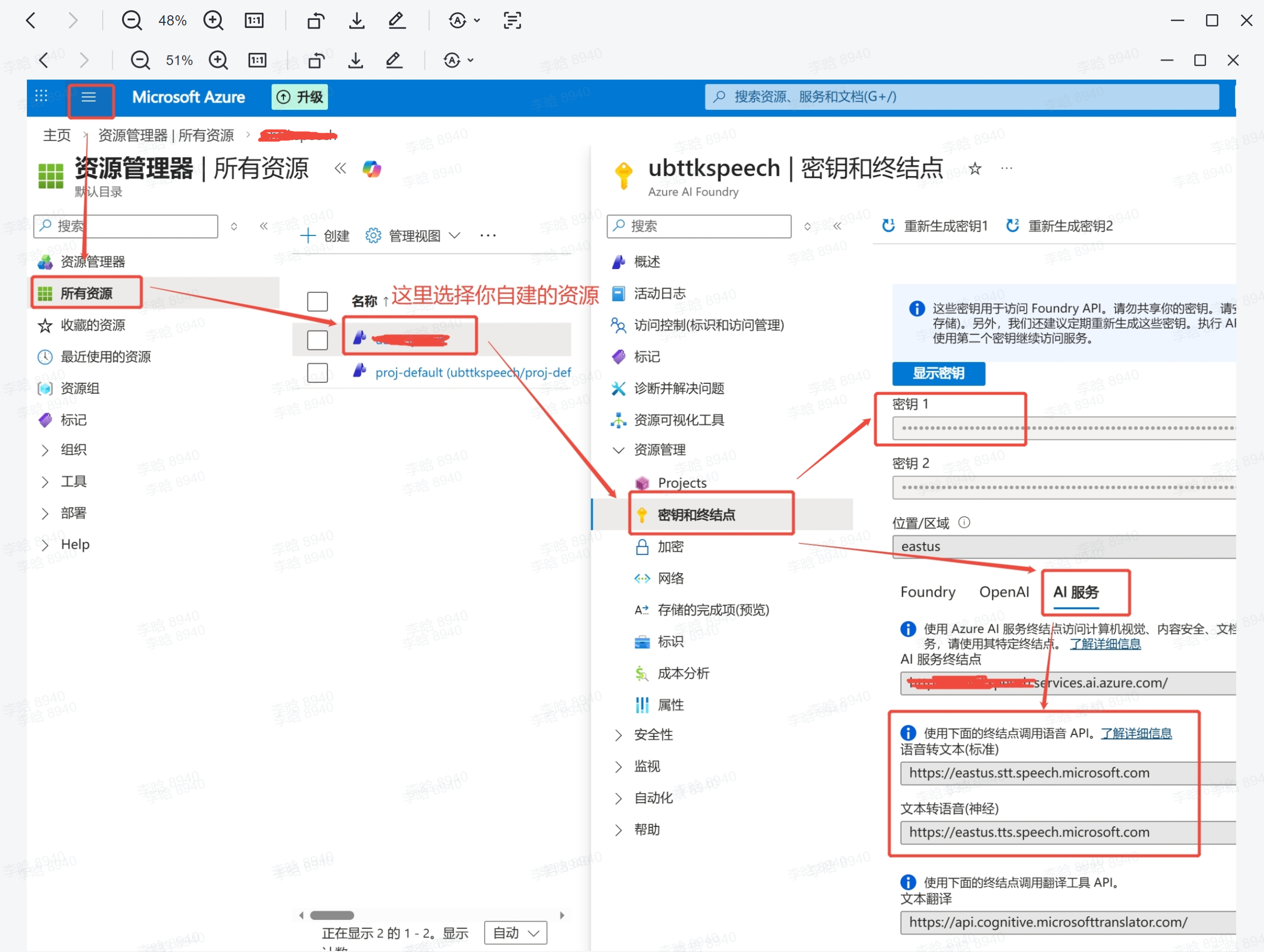
The "Key" is your SPEECH_KEY — use the copy button on the right.
Under "AI Services" you can find the STT and TTS endpoints. Note that the first part of the domain (e.g., eastus) is the region identifier. For details, refer to the Official Documentation.
Recognition Language
LANGUAGE=zh-CN
This parameter specifies the language for Microsoft STT recognition. For available values, refer to the Official Documentation.
Synthesis Voice
VOICE_NAME=sl-SI-RokNeural
# VOICE_NAME=it-IT-AlessioMultilingualNeural
# VOICE_NAME=ko-KR-HyunsuMultilingualNeural
# VOICE_NAME=ja-JP-MasaruMultilingualNeural
# VOICE_NAME=zh-CN-Xiaoxiao:DragonHDFlashLatestNeural
# VOICE_NAME=en-US-AvaMultilingualNeural
# VOICE_NAME=de-DE-SeraphinaMultilingualNeural
# VOICE_NAME=es-ES-ArabellaMultilingualNeural
# VOICE_NAME=fr-FR-LucienMultilingualNeural
This parameter specifies the voice for speech synthesis. For all available values, refer to the Official Documentation.
Azure’s documentation is not entirely accurate, not all the voices listed are actually supported.
System Prompt
SYS_MESSAGE="You are an intelligent assistant developed by UBTech, named Walker TienKung. Keep your answers concise and clear, within 100 words when possible, and respond in Slovenian."
This parameter sets the system prompt used by the LLM in this project.
Interrupt Words
INTERRUPT_WORDS=""
Interrupt words work as follows: while TienKung is playing audio, it also continues listening. When the received audio is transcribed by STT and the text is detected to contain an interrupt word, playback stops and the system enters listening mode to await the user's question. If no interrupt word is detected, the utterance is ignored. Multiple interrupt words can be configured, separated by commas.
3. Develop
First, log in to the Orin board with IP 192.168.41.2.
-
Clone:
cd ~ && git clone https://github.com/UBTEDU-OPEN/tkvoice.git -
Install python package, compile:
cd tkvoice
pip install azure-cognitiveservices-speech==1.47.0 openai==2.7.1
rm -rf build install log && colcon build --packages-select audio_message audio_service -
Source:
source install/setup.bash -
Start the application using the launch file:
ros2 launch audio_service asr_llm_tts_process_launch.py -
Chat:
The microphone array mounted on the 3588s by Tienkung is directional, capturing sound primarily within a roughly 60-degree conical area in front of the array. During conversations, the sound source (i.e., the speaker) needs to be within this spatial range; otherwise, the microphone array will not pick up the audio.
4. Run
First, log in to the Orin board with IP 192.168.41.2.
cd ~/tkvoice
# start
./tkvoice.sh start
# stop
./tkvoice.sh stop
# restart
./tkvoice.sh restart
# status
./tkvoice.sh status
# log"
tail -f /home/nvidia/tkvoice/tkvoice.log